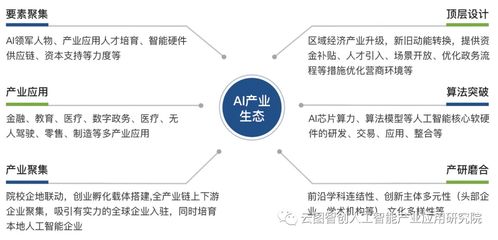
深度學習作為人工智能的核心技術,正在以前所未有的速度重塑各行各業。從醫療影像診斷到自動駕駛,從智能語音助手到金融風險預測,深度學習驅動的AI應用已經成為創新和增長的關鍵引擎。如何有效利用深度學習技術開發出真正有價值、可落地的人工智能應用呢?本文將結合世界頂級科學家在AI領域的前沿洞見,為您系統梳理開發路徑與核心技術要點。
明確問題定義與數據基礎是成功的起點。任何人工智能應用的開發都必須始于對實際業務需求的深刻理解。開發者需要與領域專家緊密合作,將復雜的現實問題轉化為具體的、可量化的機器學習任務。例如,在醫療領域,這可能意味著將“輔助醫生診斷肺癌”的目標轉化為“基于CT影像的肺結節分類與分割”任務。與此數據是深度學習的“燃料”。確保數據的規模、質量和標注的準確性至關重要。頂級科學家們常常強調,一個高質量的專用數據集,其價值有時甚至超過一個復雜的模型架構。因此,在項目初期,投入資源進行數據采集、清洗和標注,是后續所有工作的基石。
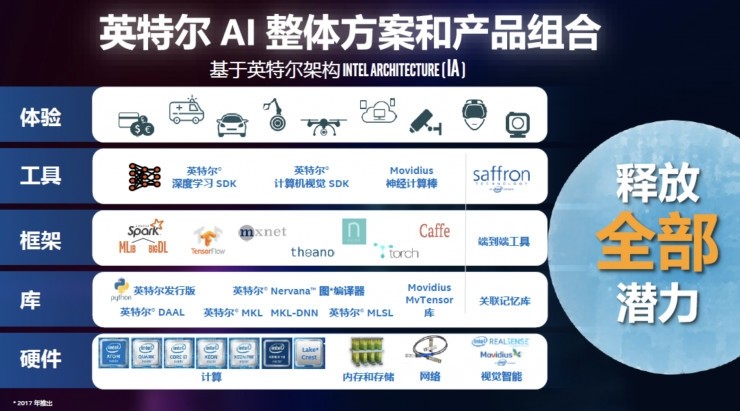
模型的選擇、設計與訓練構成了技術核心。在深度學習領域,模型架構日新月異。開發者不必總是從零開始,而是可以站在巨人的肩膀上。對于圖像識別,卷積神經網絡(CNN)及其變體(如ResNet、EfficientNet)是成熟的選擇;對于自然語言處理,Transformer架構(如BERT、GPT系列)已成為主流。關鍵在于根據任務特性進行適配與優化。訓練過程則是一門平衡的藝術,涉及損失函數的設計、優化器的選擇(如Adam、SGD)、學習率的調整以及防止過擬合的策略(如數據增強、Dropout、正則化)。世界頂級實驗室的實踐表明,采用系統化的實驗跟蹤與管理工具(如MLflow、Weights & Biases),能夠高效地迭代模型,加速開發進程。
從模型到產品:工程化與部署是關鍵一躍。一個在實驗環境中表現優異的模型,距離成為一個穩定、可靠的產品還有很長的路。模型壓縮(如剪枝、量化)和加速推理技術(如使用TensorRT、OpenVINO)對于在資源受限的邊緣設備(如手機、物聯網設備)上部署至關重要。構建完整的AI應用管道(Pipeline)——包括數據輸入、預處理、模型推理、后處理以及結果輸出——并確保其可擴展性、穩定性和低延遲,是工程團隊的核心挑戰。微服務架構和容器化技術(如Docker、Kubernetes)已成為現代AI系統部署的標準實踐。
倫理考量與持續迭代是不可或缺的維度。頂級科學家們在演講中不斷呼吁,AI應用的開發必須嵌入倫理設計。這包括評估并減輕模型的偏見(Bias),確保其決策的公平性;重視數據的隱私保護(如采用聯邦學習);以及保證系統的透明度和可解釋性,尤其是在醫療、司法等高風險領域。開發并非在部署后結束,而是一個持續監控、評估和更新的循環。通過收集生產環境中的新數據(并妥善處理數據漂移問題),不斷重新訓練和優化模型,才能使AI應用長久保持其有效性和競爭力。
使用深度學習開發人工智能應用是一個融合了領域知識、數據科學、算法創新與軟件工程的系統性工程。它要求開發者不僅緊跟技術前沿(如自監督學習、大語言模型的新進展),更要深刻理解應用場景,并以負責任的態度將技術轉化為造福社會的產品。正如一位頂尖AI科學家所言:‘最好的技術是那些看不見的技術,它們無縫融入生活,切實解決了問題。’ 這應當是所有AI應用開發者的終極目標。