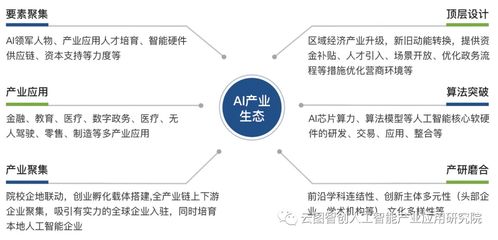
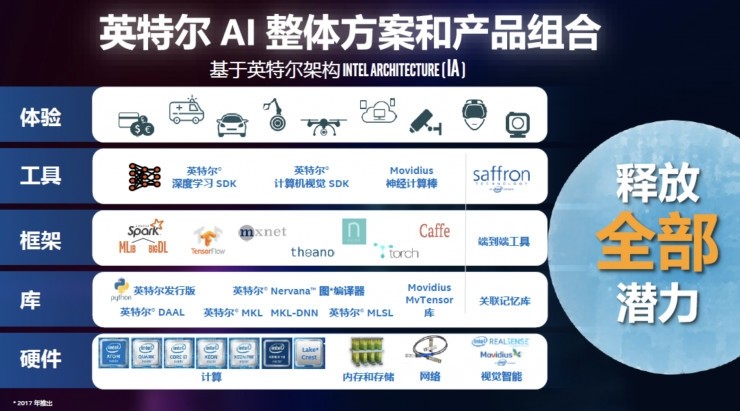
隨著人工智能技術的飛速發展,大型AI模型(如GPT、BERT等)已從研究實驗室走向產業應用,成為推動數字化轉型的核心引擎。在這一進程中,我們不僅見證了其強大的能力,也面臨著諸多技術、倫理與商業化的邊界與挑戰。本文將深入探討AI大模型的現狀、邊界問題、應對策略以及在產品技術開發中的實踐路徑。
一、AI大模型的輝煌成就與固有邊界
AI大模型在自然語言處理、計算機視覺、內容生成等領域取得了突破性進展。例如,GPT系列模型能夠生成流暢的文本,DALL-E可創作逼真的圖像,這些成果彰顯了模型在“感知”與“創作”層面的強大潛力。大模型的邊界也逐漸顯現:
- 算力與能耗的瓶頸:訓練千億級參數模型需要巨大的計算資源,導致高昂的成本和能源消耗,限制了中小企業的參與。
- 數據依賴與偏見風險:模型性能高度依賴于訓練數據,數據中的偏見可能被放大,引發公平性爭議。
- 可解釋性與可控性不足:大模型常被視為“黑箱”,其決策過程難以理解,在醫療、金融等高風險領域應用受限。
- 泛化能力與常識缺失:盡管模型能處理復雜任務,但在需要深層推理或常識判斷的場景中,仍可能出現荒謬輸出。
二、應對挑戰的策略:從技術優化到生態共建
面對這些邊界,行業需采取多維策略以推動可持續發展:
- 技術層面:通過模型壓縮、分布式訓練、低功耗芯片研發來降低算力需求;采用聯邦學習、差分隱私等技術保護數據安全與隱私;開發可解釋性AI工具,提升模型透明度。
- 倫理與治理:建立數據清洗與偏見檢測機制,制定行業倫理準則,加強監管框架,確保AI系統的公平、可靠。
- 生態協作:推動開源模型與共享數據集,鼓勵產學研合作,降低技術門檻,促進創新生態的繁榮。
三、AI人工智能產品技術開發的實踐路徑
在實際的產品技術開發中,團隊需將策略轉化為具體行動,以實現大模型的落地應用:
- 需求導向的模型選擇:避免盲目追求“大而全”,根據應用場景(如客服、創作助手、數據分析)選擇合適的模型架構,平衡性能與成本。
- 迭代式開發與測試:采用敏捷開發方法,結合A/B測試與用戶反饋,持續優化模型輸出質量,特別是在邊緣案例中提升魯棒性。
- 人機協同設計:將AI作為增強人類能力的工具,而非替代品。例如,在內容審核系統中,AI進行初步篩選,人工負責最終決策,確保效率與準確性兼顧。
- 全生命周期管理:從數據收集、模型訓練到部署監控,建立完整的MLOps(機器學習運維)流程,實現模型的持續更新與性能保障。
- 案例實踐:以智能客服產品為例,通過微調大模型以適應垂直領域術語,結合情感分析模塊提升用戶體驗,同時設置人工審核環節應對復雜查詢,有效降低了誤判率。
四、未來展望:在邊界中尋找突破
AI大模型的發展仍處于早期階段,邊界與挑戰并存,但也孕育著無限機遇。隨著量子計算、神經形態芯片等新技術的興起,算力瓶頸有望緩解;跨模態學習與因果推理的進步,或將賦予模型更接近人類的智能。在產品開發中,我們應保持審慎樂觀,以用戶價值為核心,推動AI技術向更安全、普惠、高效的方向演進。
深入探索AI大模型的邊界與挑戰,不僅需要技術上的創新,更離不開策略上的謀劃與實踐中的打磨。只有通過跨領域的協作與持續迭代,我們才能在這場人工智能革命中,真正釋放大模型的潛力,造福社會與經濟。